

Silvan Melchior
Lead Data Scientist
Dr. Gabriel Krummenacher
Head of Data Science
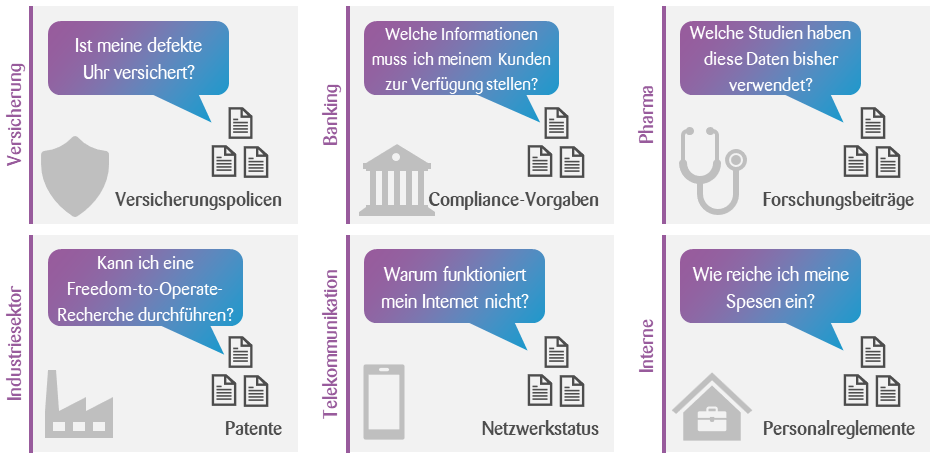
Seit der Veröffentlichung von ChatGPT ist mehr als ein Jahr vergangen. Wir sind mittlerweile in der Lage, jenen Large Language Model (LLM)-Anwendungsfall zu identifizieren, der den grössten Einfluss hat: Chatbot-basierte Frage-Antwort-Systeme für proprietäre Kundendaten. Die Nachfrage erstreckt sich über alle Branchen: Wir haben in Zusammenarbeit mit einer Versicherungsgesellschaft ein System entwickelt, das unter anderem folgende Frage beantworten kann: «Ist meine Uhr im Rahmen meiner aktuellen Police versichert?» Gemeinsam mit einer Bank haben wir eine Lösung realisiert, die Fragen zu gesetzlichen Bestimmungen beantwortet, und mit einem Telekommunikationsanbieter ein System, das bei alltäglichen Kundenanfragen hilft.
Die Technik, die hinter all diesen Anwendungsfällen steckt, wird Retrieval Augmented Generation (RAG) genannt. Dabei werden ein LLM und ein Retrieval-System kombiniert, sodass das LLM nach relevanten Informationen ausserhalb seiner Trainingsdaten suchen kann, um dann eine qualifizierte Antwort auf jede Anfrage zu generieren. Mit diesem Ansatz lässt sich das Wissen eines Modells ohne weitere Feinabstimmung leicht aktualisieren oder erweitern, und Halluzinationen werden massiv reduziert. Dieser Ansatz hat sich bereits als Schlüsselbestandteil vieler neuer LLM-gestützter Produkte erwiesen, vor allem von Microsoft Copilot.
Obwohl diese Produkte für Unternehmen in bestimmten Szenarien von Nutzen sein können, haben wir in der Vergangenheit häufig Situationen beobachtet, in denen sie nicht ausreichten:
- Eine Standardlösung liefert unter Umständen keine zufriedenstellenden Ergebnisse, zum Beispiel mit falschen Antworten. Dies ist insbesondere dann der Fall, wenn mit einer Anwendung komplexere Anforderungen verbunden sind wie domänenspezifische Daten oder inhärente Strukturen innerhalb der Daten.
- Die Daten können sich an einem Ort befinden, der für Standardtools aufgrund technischer und/oder rechtlicher Beschränkungen nicht zugänglich ist. Dies gilt beispielsweise für proprietäre Softwareumgebungen oder lokale Infrastrukturen.
- Die Daten können heterogener Art sein wie etwa Datenbanken, Diagramme oder Formulare, sodass sie von einem Standardtool nicht verwendet werden können.
- Lizenzierungssystem und Kostenstruktur passen möglicherweise nicht zu den Anforderungen des Unternehmens.
Durch den Einsatz einer mit RAG erstellten individuellen Lösung können Sie diese Einschränkungen effizient umgehen und gleichzeitig von den in den letzten Monaten und Jahren erzielten Fortschritten der generativen KI profitieren. Je nach Anwendungsfall kann es sich dabei um eine Erweiterung bestehender Lösungen (z. B. die OpenAI-Assistenten-API) oder um eine individuellere Lösung handeln. Dabei können potenziell grosse Open-Source-Sprachmodelle verwendet werden, die auf einer beliebigen Infrastruktur eingesetzt werden.
Im zweiten Teil dieses Blogposts diskutieren wir zunächst die Grundprinzipien der RAG aus einer technischen Perspektive. Anschliessend werden wir die Schwachstellen der grundlegenden Ansätze herausarbeiten und aufzeigen, welche Lösungen wir in verschiedenen Projekten dafür gefunden haben.
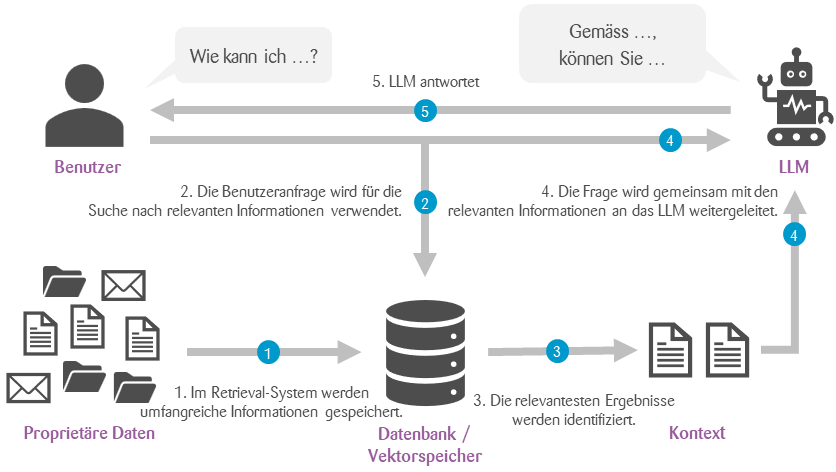
Wie funktioniert RAG
RAG kombiniert ein LLM mit einem Informationsbeschaffungssystem (Information Retrieval System). Dieses System wird bei jeder Benutzerfrage zuerst verwendet, um Informationen zur Beantwortung der jeweiligen Frage zu finden. Anschliessend werden die gefundenen Informationen zusammen mit der Benutzerfrage an das LLM weitergeleitet, damit dieses eine qualifizierte Antwort geben kann.
Das Retrieval-System basiert in der Regel auf sogenannten Einbettungen. Einbettungen nehmen einen Textabschnitt und ordnen ihn in einen mathematischen Vektorraum ein. Und zwar so, dass Texte, die von ähnlichen Dingen handeln, in diesem Vektorraum nahe beieinander liegen. Auf diese Weise können bei der Suche nach Informationen sowohl alle verfügbaren Informationen als auch die Benutzeranfrage eingebettet werden. Dann können wir diejenigen Texte identifizieren, die der Anfrage im Vektorraum am ehesten entsprechen. Diese Texte enthalten wahrscheinlich Informationen, die für die Suchanfrage relevant sind.
Ein wichtiges Element dieses Ansatzes ist das sogenannte Chunking. Dabei nehmen wir unsere Texte und zerlegen sie in kleinere Segmente (Chunks) mit beispielsweise je einigen hundert Wörtern. Diese Chunks werden dann separat eingebettet. So können wir nach jenen Textabschnitten suchen, die für uns relevant sind, anstatt nach dem ganzen Text.
Obwohl dieser einfache Aufbau in vielen Fällen erstaunlich gut funktioniert, ist er in bestimmten Fällen doch unzureichend. In der Regel treten folgende Probleme auf:
- Einbettungsbasierte Suchen bringen oft nicht die gewünschten Ergebnisse: Auch wenn sich diese Art der Suche hervorragend zur korrekten Erfassung der Bedeutung von Synonymen usw. eignet, ist sie nicht perfekt. Für bestimmte Datentypen erweisen sich manche Einbettungsmodelle sogar als recht problematisch, zum Beispiel für juristische Texte oder Firmennamen. Je grösser also die Informationsbasis wird, desto geringer ist die Wahrscheinlichkeit, die richtigen Chunks zu finden.
- Bei den Chunks fehlt der Kontext: Selbst wenn der richtige Chunk gefunden wird, handelt es sich immer noch nur um einen kleinen Teil des gesamten Textes. Da der Kontext fehlt, kann das LLM dazu verleitet werden, den Inhalt falsch zu interpretieren.
- Der One-Shot-Ansatz verhindert eine genaue Suche: Das Retrieval-System hat nur eine Chance, die richtigen Informationen zu finden. Formuliert der Benutzer die Anfrage nicht klar genug, kann es die gewünschten Informationen unter Umständen nicht liefern. Erfordern die gefundenen Informationen eine Folgefrage, kann diese nicht beantwortet werden.
Wie lässt sich die Leistung von RAG verbessern?
In den oben genannten Fällen liefert das Modell entweder gar keine oder – noch schlimmer – eine falsche Antwort. Daher gibt es mehrere Erweiterungen oder Anpassungen des grundlegenden RAG-Setups, die je nach Problemstellung hilfreich sein können.
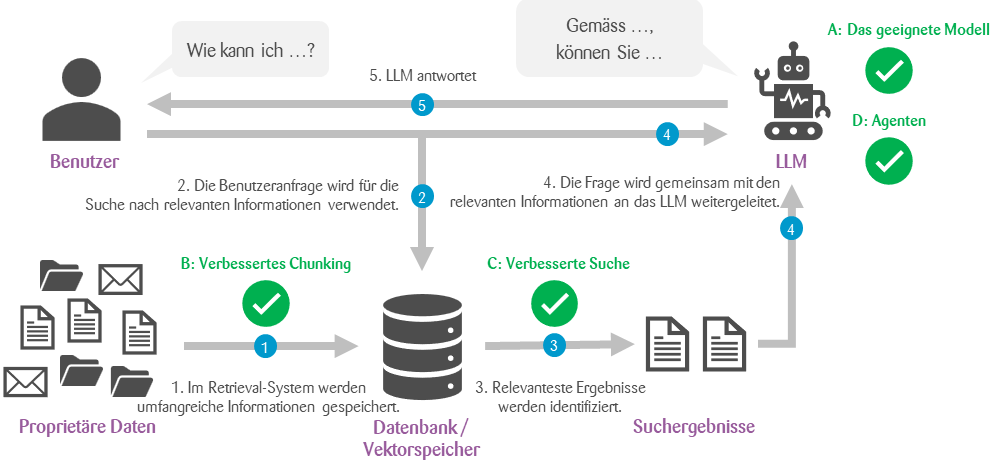
Das passende Modell
Natürlich wirkt sich die Wahl des Modells stark auf die endgültige Leistung aus. LLMs können nur eine bestimmte Menge an Informationen auf einmal verarbeiten. Daher können wir ihnen nur eine bestimmte Anzahl Chunks als Hilfe zur Beantwortung der Frage zur Verfügung stellen. Durch die Verwendung eines Modells mit einer grösseren Kontextlänge lässt sich ein RAG-System auf einfache Weise verbessern. Werden nämlich mehr Chunks einbezogen, sinkt die Wahrscheinlichkeit, dass relevante Chunks übersehen werden. Glücklicherweise haben neuere Modelle die Kontextlänge massiv erhöht. So wurde beispielsweise GPT-4 im November 2023 aktualisiert und unterstützt nun bereits 128’000 Token, was etwa 200 Seiten Text entspricht. Und im Februar 2024 kündigte Google einen Durchbruch in seiner Gemini-Serie an, die bald eine Million Tokens unterstützt.
Diese Lösung hat jedoch einen Nachteil: Je länger der Kontext ist, desto schwieriger ist es für ein Modell, die relevanten Informationen herauszufiltern. Ausserdem kommt es auch darauf an, an welcher Stelle im Kontext die Informationen bereitgestellt werden. So werden beispielsweise Informationen in der Mitte in der Regel weniger gewichtet. Nicht zuletzt erfordert die Inferenz mit sehr langen Kontexten viele Ressourcen. In der Praxis müssen also Kompromisse auf Basis einer sorgfältigen Bewertung eingegangen werden.
Die Kontextlänge ist jedoch nicht das einzige Auswahlkriterium für Ihr Modell. Handelt es sich beispielsweise um hochspezifische Daten wie medizinische Unterlagen, kann ein Modell, das auf solchen Daten trainiert wurde, einem Standardmodell überlegen sein, auch wenn es eine geringere Kontextlänge hat.
Verbessertes Chunking
Das Chunking, also das Zerlegen von Informationen in kleine, durchsuchbare Segmente, wirkt sich stark auf die Abrufleistung aus. Ist ein Chunk zu klein, kann ihn das LLM aufgrund des fehlenden Kontexts (des Originaltexts) nur schwer interpretieren. Ist ein Chunk zu gross, wird der Einbettungsvektor sehr allgemein, da der Text zunehmend unterschiedliche Themen enthält. Die Suchleistung verschlechtert sich.
Auch hier muss eine für den jeweiligen Anwendungsfall spezifische Bewertung vorgenommen werden, um die optimale Chunk-Grösse und -Überlappung zu finden. Darüber hinaus kann adaptives Chunking eingesetzt werden, bei dem nicht alle Chunks gleich gross sind. Adaptives Chunking berücksichtigt in der Regel die Dokumentstruktur (zum Beispiel Absätze) und kann wiederum Einbettungen verwenden, um die Ähnlichkeit der diskutierten Themen zwischen verschiedenen Textpassagen zu messen.
Verbesserte Suche
Wie bereits erwähnt, hat die einbettungsbasierte Suche ihre Grenzen. Eine gängige Methode, diese Suche zu verbessern, besteht darin, sie mit der klassischen, stichwortbasierten Suche zu kombinieren. Diese Kombination, oft als hybride Suche bezeichnet, erbringt in der Regel eine bessere Leistung als die reine einbettungsbasierte Suche.
Da die Anzahl Chunks, die dem LLM zugeführt werden können, begrenzt ist, findet häufig auch ein Reranking statt. Zunächst werden mehr Chunks abgerufen, als in den LLM-Kontext passen. Anschliessend werden anhand eines separaten maschinellen Lernmodells diejenigen Chunks identifiziert, die am besten passen. Dieses Modell ist zu teuer, um alle Chunks in den Daten zu berücksichtigen. Es ist aber preisgünstig genug, um mehr Chunks zu analysieren, als in den LLM-Kontext passen würden.
Schliesslich lässt sich auch die Anfrage verbessern, auf deren Basis wir die Suche vornehmen. Standardmässig wird die Benutzeranfrage verwendet. Wir können aber auch ein anderes grosses Sprachmodell damit beauftragen, diese Frage zunächst in einen passenderen Suchbegriff umzuformulieren. Dabei kann es sich um alles Mögliche handeln, von spezialisierten Schlüsselwörtern über mehrere Fragen bis hin zu potenziellen Antworten.
Agenten
Wie bereits erwähnt, hat das Retrieval-System nur eine Chance, die richtigen Informationen zu finden. Greifen wir auf einen allgemeineren Ansatz für Frage-Antwort-Systeme zurück, ändert sich dies. In diesem Fall übernimmt ein grosses Sprachmodell den gesamten Informationsbeschaffungsprozesses. Das Modell kann aktiv nach Informationen suchen, sich die Ergebnisse ansehen und gegebenenfalls nochmals mit anderen Begriffen oder nach einem anderen Thema suchen. Realisiert wird dies mit sogenannten Agentic AI. In diesem Fall kann ein grosses Sprachmodell nicht nur mit dem Benutzer sprechen, sondern stattdessen auch ein Tool verwenden, etwa eine Suchmaschine (unser Retrieval-System) oder sogar eine Datenbank für strukturierte Informationen. Dieses Paradigma kann in bestimmten Fällen sehr leistungsfähig sein. Es funktioniert aber in der Regel nur dann zufriedenstellend, wenn das grosse Sprachmodell für die Arbeit mit externen Tools trainiert ist.
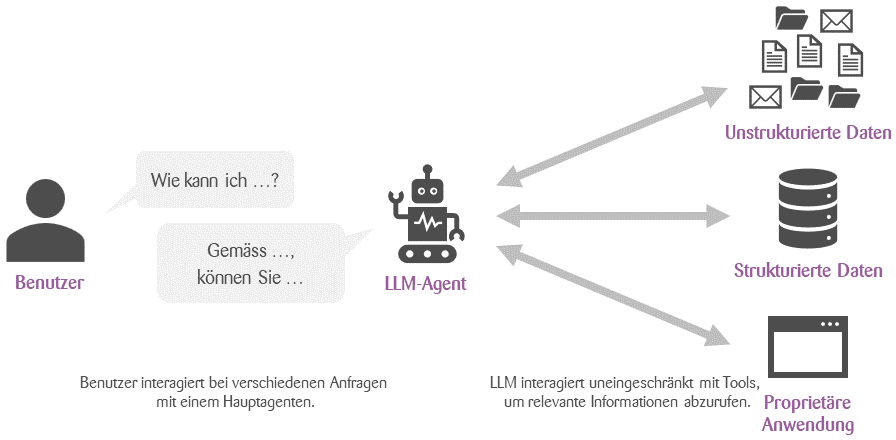
Schlussfolgerung
Wir sind zuversichtlich, dass auch in Zukunft die Kombination von LLMs mit proprietären Informationen massgeblich dazu beitragen wird, diese Modelle zunehmend nützlicher zu machen. Der Zugang zu Tools wie Suchmaschinen, aber auch zu Datenbanken mit strukturierten Informationen oder sogar die Möglichkeit, aktiv eine Aktion auszulösen (wie das Senden einer E-Mail oder das Hinzufügen einer Zeile zu einer Kalkulationstabelle), eröffnen zahlreiche neue Anwendungsfälle, die es bisher nicht gab. Wir betreten eine neue Welt der Automatisierung, Augmentation und Benutzerinteraktion.
Dank unseres Know-hows im Bereich generativer KI-Lösungen und unserer Erfahrung aus vielen Projekten in allen grösseren Branchen können wir Sie bei Ihrer generativen KI-Transformation unterstützen. Unser Angebot umfasst die Beratung zu Portfolios von Anwendungsfällen, Entdeckungsphasen von spezifischen Anwendungsfällen, das Prototyping dieser Fälle und die Implementierung und Integration vollwertiger massgeschneiderter generativer KI-Lösungen.


